|
|

|
Introduction to the topic of the workshop
Traditional methods in machine learning and statistics provide data-driven models for predicting one-dimensional targets,
such as binary outputs in classification and real-valued outputs in regression. According to a general definition, the targets in multi-target prediction problems might be characterized by diverse data types, such as binary, nominal, ordinal and real-valued variables, but also rankings and relational structures, representing different entities of interest. Moreover, they often exhibit specific relationships, in the sense of being structured as a tree-shaped hierarchy or a directed acyclic graph, or being characterized by mutual exclusion, parent-child and other types of relationships. Specific multi-target prediction problems have been studied in a variety of subfields of machine learning and statistics, such as multi-label classification (prediction of multiple binary targets), multivariate regression (prediction of multiple numerical targets), sequence learning (ordered targets of varying length), structured output prediction (targets with inherent structure), preference learning (prediction of a preference relation between multiple targets, as in label ranking), multi-task learning (prediction of multiple targets in different but related domains) and collective learning (prediction for dependent observations). Objectives and targeted audience
Despite their commonalities, work on solving problems in the above domains has typically been performed in isolation, without much interaction between the different sub-communities.
Moreover, several of the problems have been studied in different communities under different names.
Sometimes there is even terminological confusion within the same community.
Despite the encouraging progress that has been made in the last decade, the current understanding of multi-target learning tasks and methods remains shallow. Further communication and education on the fundamental insights for this type of problems is still required. To date, it remains unclear which of the numerous approaches recently proposed performs better and under what assumptions. Therefore, the workshop intends to cover an overview of existing methods, while focussing on cross-domain methodologies. With the workshop we aim to attract both researchers that are already active in one of the above domains, as well as researchers with little or no prior experience in multi-target prediction. As such, we believe that the workshop will attract ECML attendees from diverse subfields of machine learning and with different background. |


 In recent years, novel application domains have triggered fundamental research on more complicated problems where multi-target predictions are required.
Such problems arise in diverse application domains, such as document categorization, tag recommendation of images, videos and music, information retrieval, medical decision making, drug discovery, marketing, biology, geographical information systems, etc.
In recent years, novel application domains have triggered fundamental research on more complicated problems where multi-target predictions are required.
Such problems arise in diverse application domains, such as document categorization, tag recommendation of images, videos and music, information retrieval, medical decision making, drug discovery, marketing, biology, geographical information systems, etc.
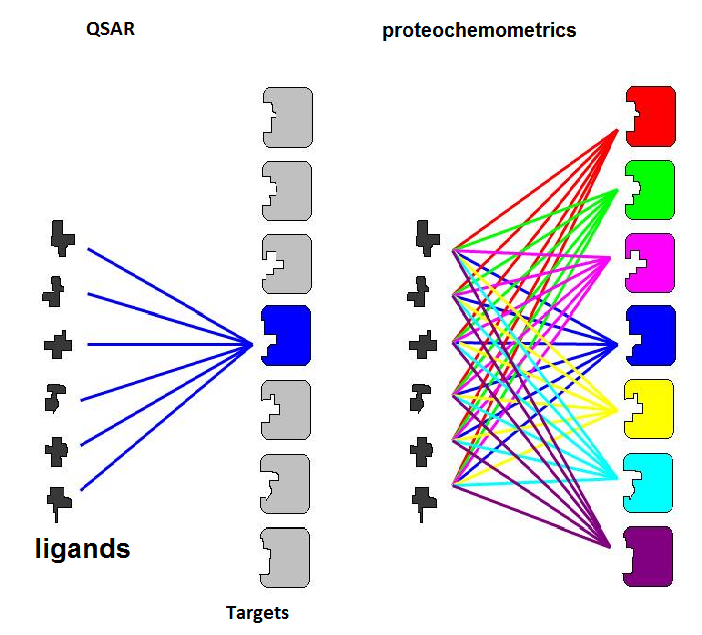 The main goal of the workshop is to present a unifying overview of the above-mentioned subfields of machine learning,
by focusing on the simultaneous prediction of multiple, mutually dependent output variables.
In the different subfields of machine learning that cover multi-target prediction it has been acknowledged by many authors that it is important to explicitly model the dependencies between the predicted targets.
As a result of numerous discussions with experts in the above-mentioned domains, we are convinced that existing solutions can be brought to a fruitful cross-fertilization.
The main goal of the workshop is to present a unifying overview of the above-mentioned subfields of machine learning,
by focusing on the simultaneous prediction of multiple, mutually dependent output variables.
In the different subfields of machine learning that cover multi-target prediction it has been acknowledged by many authors that it is important to explicitly model the dependencies between the predicted targets.
As a result of numerous discussions with experts in the above-mentioned domains, we are convinced that existing solutions can be brought to a fruitful cross-fertilization.